以為我要講什麼新東西嗎?昨天講了字串,今天又要講字串,那遵循這個狀況,開頭也先繼續講 Python 之禪好了。
所謂的 PEP 20 就是所謂的 The Zen of Python(Python 之禪),其中 PEP 代表的意思是 Python Enhancement Proposals,翻譯成中文可以理解為「編寫 Python 的增進建議」,而 PEP 20 的 20 代表的是「由 Python 開發者 Tim Peters 所倡導的 20 條箴言」。
但實際上只有 19 條,至於為什麼只有 19 條,請看 VCR!(沒啦,請看昨天第四天的復健文章。)
假設有一個字串 GEEKSFORGEEKS,如果我想從中取出單字 O,有任何方法可以做到這件事嗎?
不能。(文章結束,開玩笑的!)
在 Python 中,我們可以將索引值 index 視為每個單字所在的位置編號,而這個編號是從 0 開始計算,之所以會從 0 開始,可以思考成「有一排櫃子依序排放,而第一個的櫃子是從原點 0 開始擺放,佔據了 0 到 1 之間的格式」,所以 index 指的是起始位置,而非數量編號。
(索引值 index 的示意圖)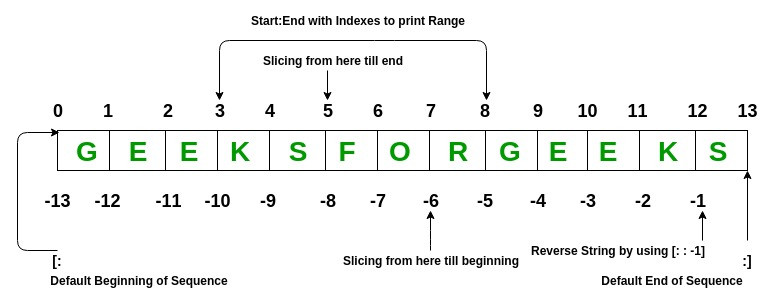
所以按照上圖的說明,字串 'GEEKSFORGEEKS' 的每一個單字可以從 0 排序到 12(13 是終點),我們可以透過 print('GEEKSFORGEEKS')[6] 取得單字 O。
從圖片中,我們也可以得知,如果我們要從字串的最尾端開始計算索引值 index,會從 -1 開始計算到 -13,所以如果要反向取得 O 的話,這時候我們也可以透過 print('GEEKSFORGEEKS')[-7] 得到相同的結果。
假設我們希望從字串 'GEEKSFORGEEKS' 中取得前面的 GEEKS,做得到嗎?
當然!
稍早我們學會了索引值 index,而切片 slicing 則是使用索引值標註切割的頭尾(起始點與終點),進而擷取出字串的片段,以取出 GEEKS 為例,我們可以使用 print('GEEKSFORGEEKS'[0:5]) 印出 GEEKS。
如果我們想將 'GEEKSFORGEEKS' 反轉成 'SKEEGROFSKEEG',想當然爾一定做得到,不然我也不用在這邊賣關子,答案是我們可以使用 print('GEEKSFORGEEKS'[::-1]) 進行反向排序,達成我們想要的效果。
在 Python 中,每個資料型態 data types 都有自己專屬的方法 method,方法 method 就像是已經編寫好的內建功能,讓我們可以快速完成一些特定但常見的任務,像是昨天所提到的 format() 就是字串的其中一種方法。
這邊列舉幾個常見的 string methods:
capitalize()
challenge = 'thirty days of python'
print(challenge.capitalize()) # 'Thirty days of python'
count()
challenge = 'thirty days of python'
print(challenge.count('y')) # 3
print(challenge.count('y', 7, 14)) # 1,7 代表的是起始索引值,14 則是結尾的索引值
print(challenge.count('th')) # 2`
endswith()
challenge = 'thirty days of python'
print(challenge.endswith('on')) # True
print(challenge.endswith('tion')) # False
find()
challenge = 'thirty days of python'
print(challenge.find('y')) # 5
print(challenge.find('th')) # 0
print(challenge.find('z')) # -1,如果找不到的話,會返回 -1
rfind()
challenge = 'thirty days of python'
print(challenge.rfind('y')) # 16
print(challenge.rfind('th')) # 17
print(challenge.rfind('z')) # -1,如果找不到的話,會返回 -1
isalnum()
challenge = 'ThirtyDaysPython'
print(challenge.isalnum()) # True
challenge = '30DaysPython'
print(challenge.isalnum()) # True
challenge = 'thirty days of python'
print(challenge.isalnum()) # False,因為空格不能算單字
challenge = 'thirty days of python 2019'
print(challenge.isalnum()) # False
isalpha()
challenge = 'thirty days of python'
print(challenge.isalpha()) # False,因為空格不能算單字
challenge = 'ThirtyDaysPython'
print(challenge.isalpha()) # True
num = '123'
print(num.isalpha()) # False
isdecimal()
print("12345".isdecimal()) # True
print("123.45".isdecimal()) # False,小數點在這邊不算數字
print("12345a".isdecimal()) # False
print("Ⅻ".isdecimal()) # False,羅馬數字在這裡不算數字
print("\u00B2") # False
isdigit()
print("12345".isdigit()) # True
print("123.45".isdigit()) # False, decimal point is excluded
print("12345a".isdigit()) # False
print("Ⅻ".isdigit()) # True, Roman numbers are included
print("²³".isdigit()) # True, superscript numbers are included
isidentifier()
challenge = '30DaysOfPython'
print(challenge.isidentifier()) # False, because it starts with a number
challenge = 'thirty_days_of_python'
print(challenge.isidentifier()) # True
islower()
challenge = 'thirty days of python'
print(challenge.islower()) # True
challenge = 'Thirty days of python'
print(challenge.islower()) # False
isupper()
challenge = 'thirty days of python'
print(challenge.isupper()) # False
challenge = 'THIRTY DAYS OF PYTHON'
print(challenge.isupper()) # True
join()
web_tech = ['HTML', 'CSS', 'JavaScript', 'React']
result = ' '.join(web_tech)
print(result) # 'HTML CSS JavaScript React'
web_tech = ['HTML', 'CSS', 'JavaScript', 'React']
result = ' #'.join(web_tech)
print(result) # 'HTML #CSS #JavaScript #React'
而以上這些僅是字串能使用的方法中的冰山一角,不過就算不知道全部的方法也不用太緊張,因為有許多的方法,在我們需要的時候,會透過搜尋、詢問慢慢認識這些方法,多使用、多看就會不小心記得了。
今天文章寫到一半時,發現不小心把昨天的鐵人賽文章標題誤植第三天了,嚇出了幾滴冷汗,因為稍早才看到有一位參賽者發文誤選了發文的類別,導致他在第十六天未能成功繼續鐵人賽發文,真的好可惜。
一下子也過完第五天了,六分之一看起來也沒想像中的難嘛!(開始講大話)

